Work Completed
So far, we've set up a suite of test cases in order to measure both the correctness and the performance of our parallel algorithm as we keep developing it. This comprehensive test suite consists of test cases with varying sizes (number of points) as well as overall shapes, currently either circle or square. We plan to add even more types of test cases later when we do our thorough performance analysis so that we have a robust understanding of how well our algorithm performs. In order to give our parallel convex hull algorithm something to compare to, we've also implemented a simple sequential convex hull algorithm based on Graham scan.
We've also implemented the parallel randomized algorithm specified in Guy Blelloch's paper. This algorithm relies on the idea of ridges, which are the points at which two facets (edges) of the convex hull meet. If for a particular ridge both if its incident facets can 'see' a point in our set, then we remove this ridge. Otherwise, we construct a new ridge by removing one facet and replacing it with two new facets connected to one of the points that that facet could see. This algorithm is work-efficient, but our single-threaded implementation has a roughly 4x slowdown over the fast version using Graham scan. We then sought to parallelize this algorithm using OpenMP. In particular, we've experimented with parallelizing two different parts: visible set construction and recursive calls. The visible set construction is a highly parallel operation, as each point is independently evaluated for visibility. After parallelizing the recursive step by reordering the computation of the call graph to be done layer-by-layer instead of depth-first, we found that our span was indeed \(\mathcal{O}(\log n)\), as expected.
Progress W.R.T. Goals
We've been moving on pace with the goals and schedule we originally defined in our project proposal. We've already completed our first 3 week's goals, namely the fast sequential, sequential version of parallel, and parallel implementations. By using an alternative hashmap implementation, we've been able to achieve decent scaling at low thread counts. This is almost exactly where we expected to be at this point, if not a little ahead. From here on, the remaining work is mostly profiling and performance improvement, since we already have a correct implementation.
Poster Session Plans
For our poster, our plan is to include:
- A high level overview of the convex hull problem, including a diagram
- An overview of the parallel algorithm, including pseudocode
- An overview of what we did to implement this parallelism, possibly including code extracts, as well as details on challenges encountered
- Performance results, including scaling graphs across thread count, problem size, etc.
- Cache performance information
- Call graph information to demonstrate \(\mathcal{O}(\log n)\) span
Preliminary Results
Based on our current implementation of the parallel convex hull algorithm, we've collected some very preliminary results so far as a testament to the progress we've made over the past three weeks.
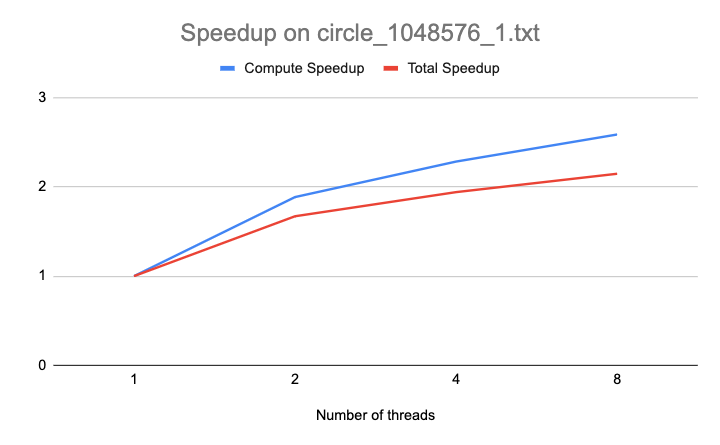
Our speedup graph on one of the inputs with 1048576 points can be seen above. As shown, it has close to perfect compute speedup on 2 threads but the speedup starts to plateau as the number of threads increases, likely due to the overhead of the dynamic scheduler as well as idle threads on layers with fewer tasks than threads.
Challenges
The major challenges we currently face are related to figuring out how to improve our speedup factor on higher thread counts. Although we haven't measured on PSC yet, we can expect to see either a stagnating or even decreasing speedup as the number of threads scales even higher. This is because many of the initial and final layers in the dependency graph of our computation have fewer ridges than available threads, thus leaving some threads idle during those iterations. We also still have largely sequential computation on the \(C\) map, in particular when computing the least visible point and also the visible set of the new facet formed. Thus, we are faced with the challenge of extracting more speedup and work from these possible stages in the algorithm.
Updated Schedule
Our updated schedule is as follows:
| Time | Task | Who |
|---|---|---|
| 04/14 ~ 04/16 | Profile code to find performance bottlenecks | Cole |
| 04/14 ~ 04/16 | Upgrade testing suite with a larger variety of cases | Edward |
| 04/17 ~ 04/20 | Optimize code to achieve ideal speedup based on the bottlenecks identified | Both |
| 04/21 ~ 04/23 | Generate final benchmarks and performance measurements on GHC and PSC | Edward |
| 04/21 ~ 04/23 | Create cool visuals to be used for the final poster | Cole |
| 04/24 ~ 04/27 | Write the final project report | Both |
| 04/24 ~ 04/27 | Prepare the final presentation poster | Both |